Authors: Manuel Mendoza Hurtado, Domingo Ortiz Boyer
Abstract:
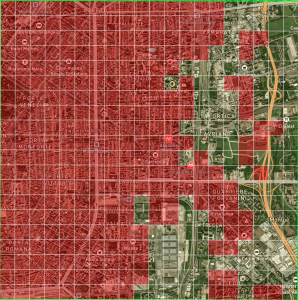
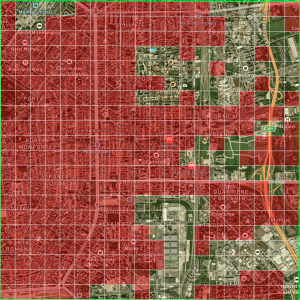
This paper presents a comparative study between clustering analysis, which is typically used in mobility scenarios, and supervised classification for the identification of home and work zones of an area. We will use a mobility dataset from the city of Milan to achieve this. Using passive mobile positioning data offers a powerful tool to study the geography and the mobility of the population. With the available data, we will try to identify workplaces and residential areas using both supervised classification and clustering. In order to generate training data for the classification model, we manually label several sub-regions of the available grid, one with random cells and another with a 20-by-20 resolution. Experimental results show that the kNN algorithm provides an acceptable accuracy that could be able to predict if a cell represent a working or a residential area for the full grid, thanks to the semi-supervised approach used in learning from a manually-labeled region. However, the results provided with k-means and k-medoids clustering show that it is not able to accomplish the former idea, instead it focuses on identifying the mobile traffic distribution around the city.